
前言
最近在网上冲浪,偶然发现了一个非常不错的网站 H 漫画网站 (hit***.la),它是一个以漫画为主要内容的网站,用户可以在上面查看和下载漫画,而且这些都是免费的,无需登录也不需要会员。体验比 E 站棒多了
这些漫画都提供给下载,可以根据自己的需要进行下载。但下载是在前端用 js 实现的,所以下载的速度比较慢,偶尔可能会下载失败。特别是没一个稳定靠谱的梯子。
因此,我决定编写一个爬虫工具,用于批量下载 H 漫画网站上的漫画,并支持多种保存格式(如图片、PDF、EPUB 等)。
一步一步的详细过程
打开目标漫画页面后,查看下网站源码,很明显看到页面采用动态加载方式。
考虑到直接从该网页 HTML 源码上获取内容可能是比较麻烦,但页面提供了基于 JS 实现的打包下载按钮,因此决定从该下载功能入手分析。
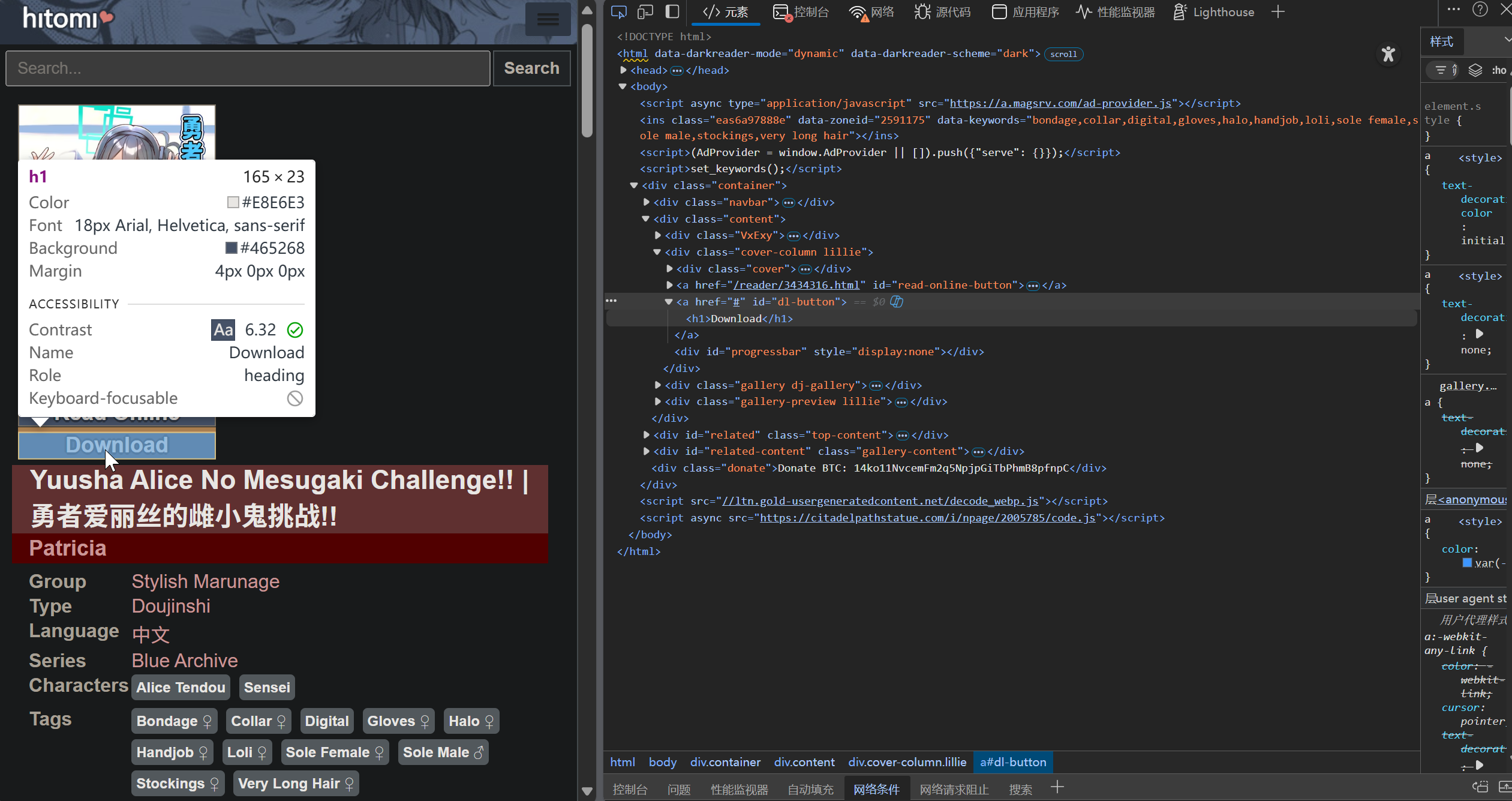
可以看到下载按钮的 id 是 dl-button,可以通过该 id 来获取下载的代码。
但我直接在控制台网络查看谁发起网络请求的不就更快?
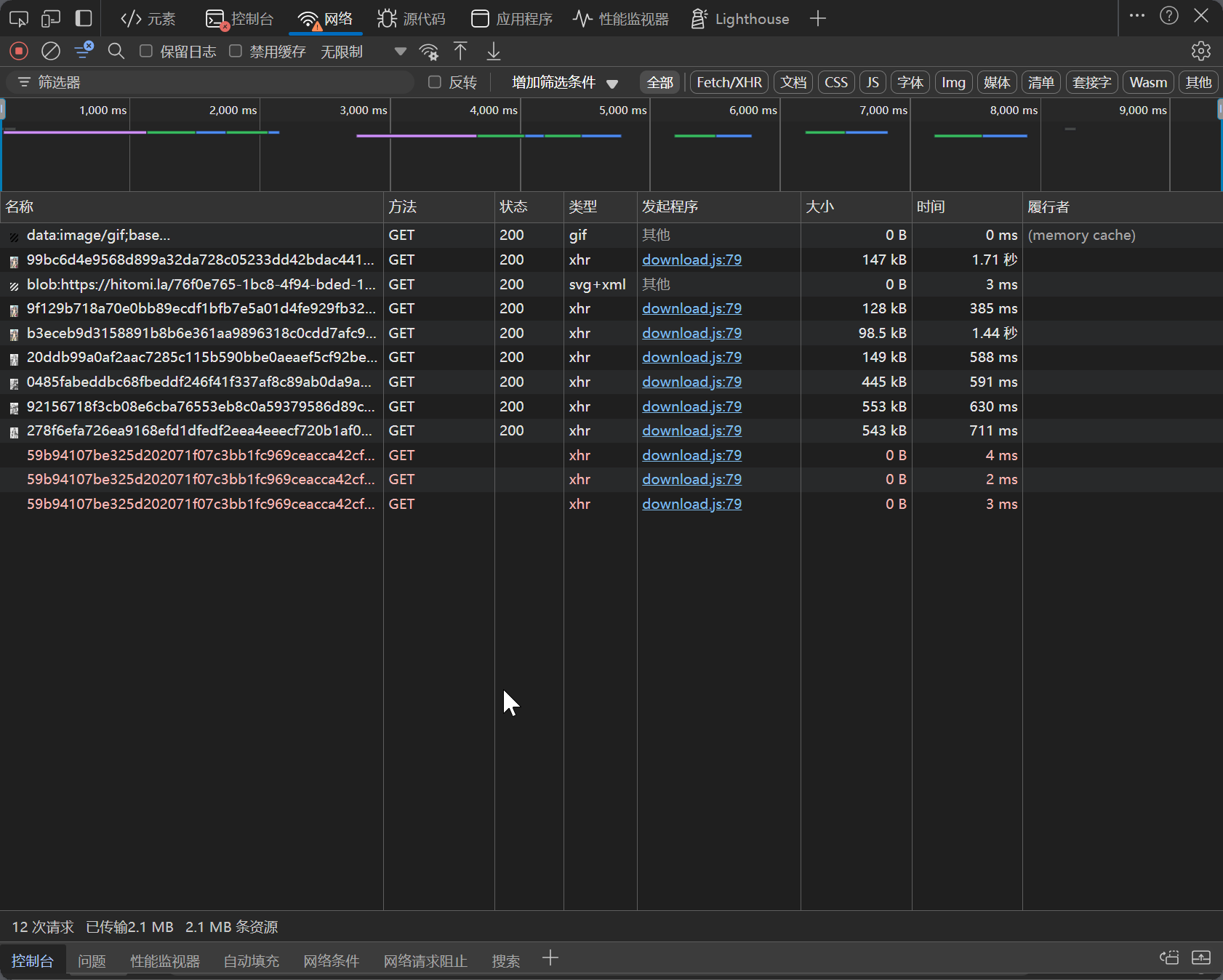
可以看到发起网络请求的是一个 download.js 文件,图片的下载链接是 https://.gold-usergenera*********.net/* 之类的。
先在控制台里搜该图片 URL,说不定能直接获取所有的图片下载链接。
但遗憾的是,控制台啥都搜不到,只能通过 download.js 来解析了。
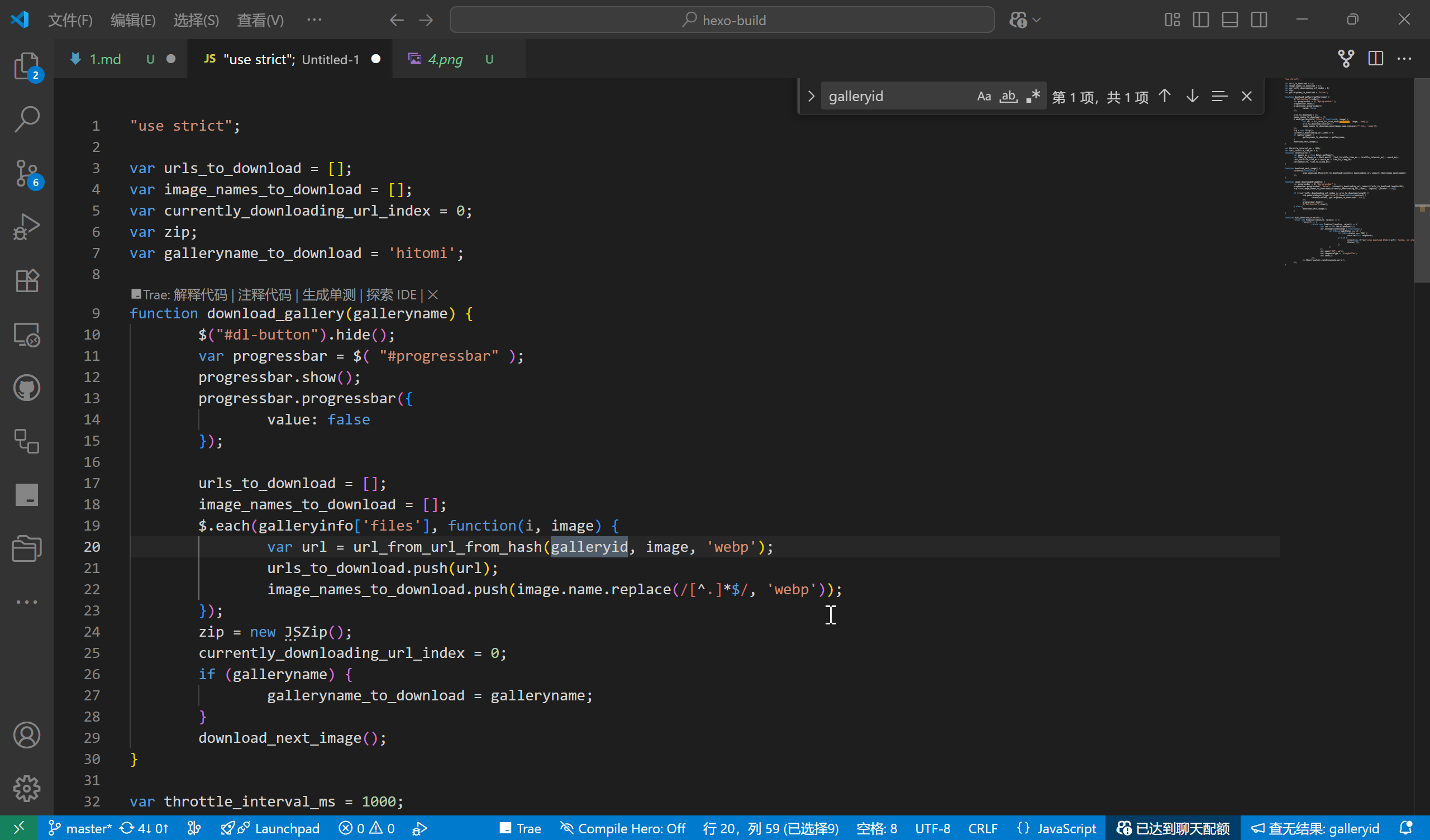
通过 download.js 可以看到,下载链接是通过一个函数 url_from_url_from_hash(galleryid,galleryinfo.files, 'webp') 来获取的,

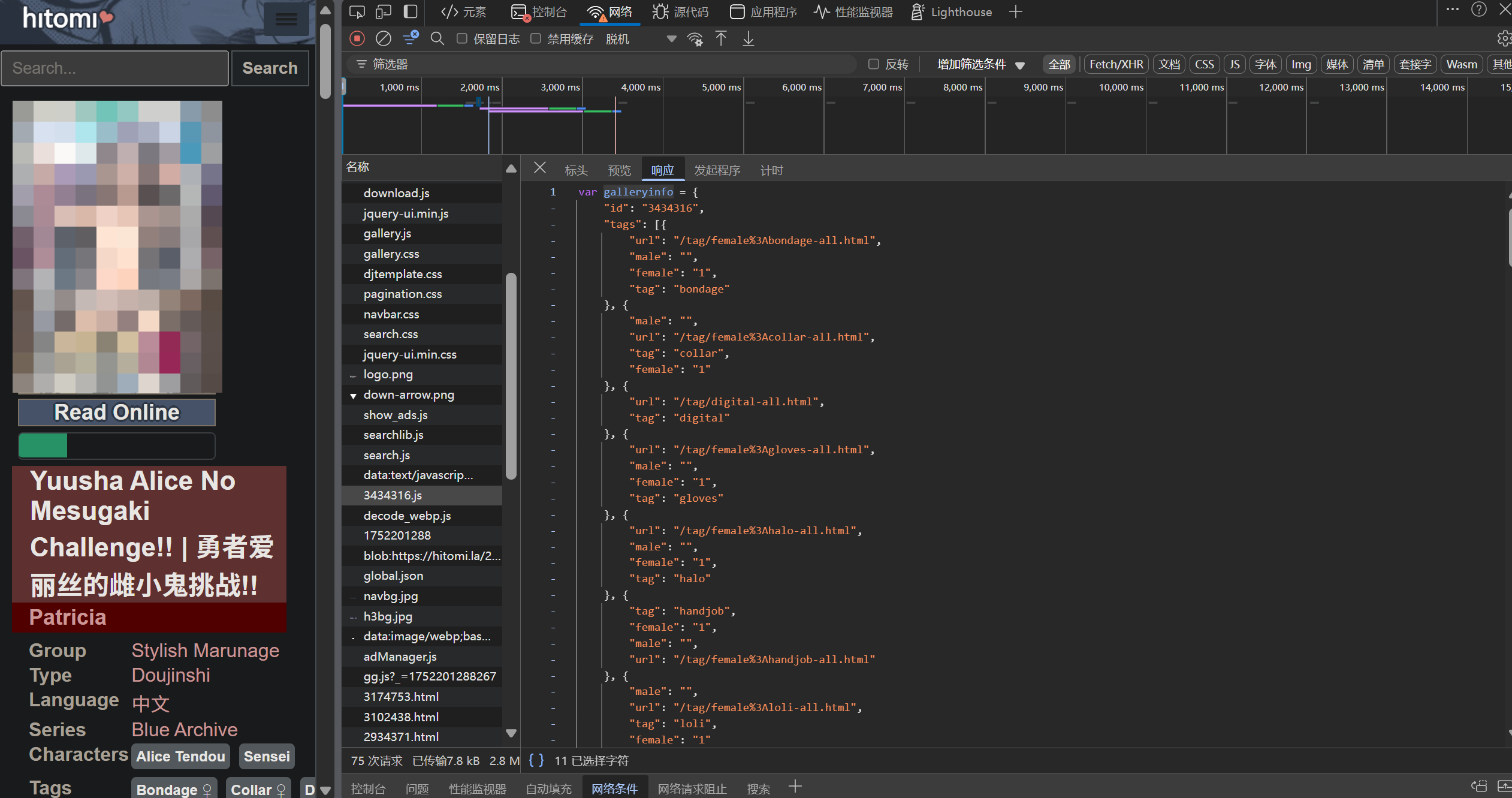
这个 object (galleryinfo) 里面存储了漫画的所有信息。在控制台搜索 galleryinfo 找到该 object 后,在控制台搜索 galleryinfo 后,确定其定义于 https://ltn.gold-usergenera**********.net/galleries/3434316.js 这个文件里的,对比 galleryinfo 一下可以发现,3434316 是该漫画的 ID,前面这部分是固定的,后面的数字是变动的。
进一步分析 HTML 源码可知,发现该 JS 文件是动态加载方式引入,原来在 HTML 是没有这段代码的 (<script src='******'></script>)。回到正文 HTML 源码,发现有一段代码,非常明显就是动态加载该 JS 文件的。
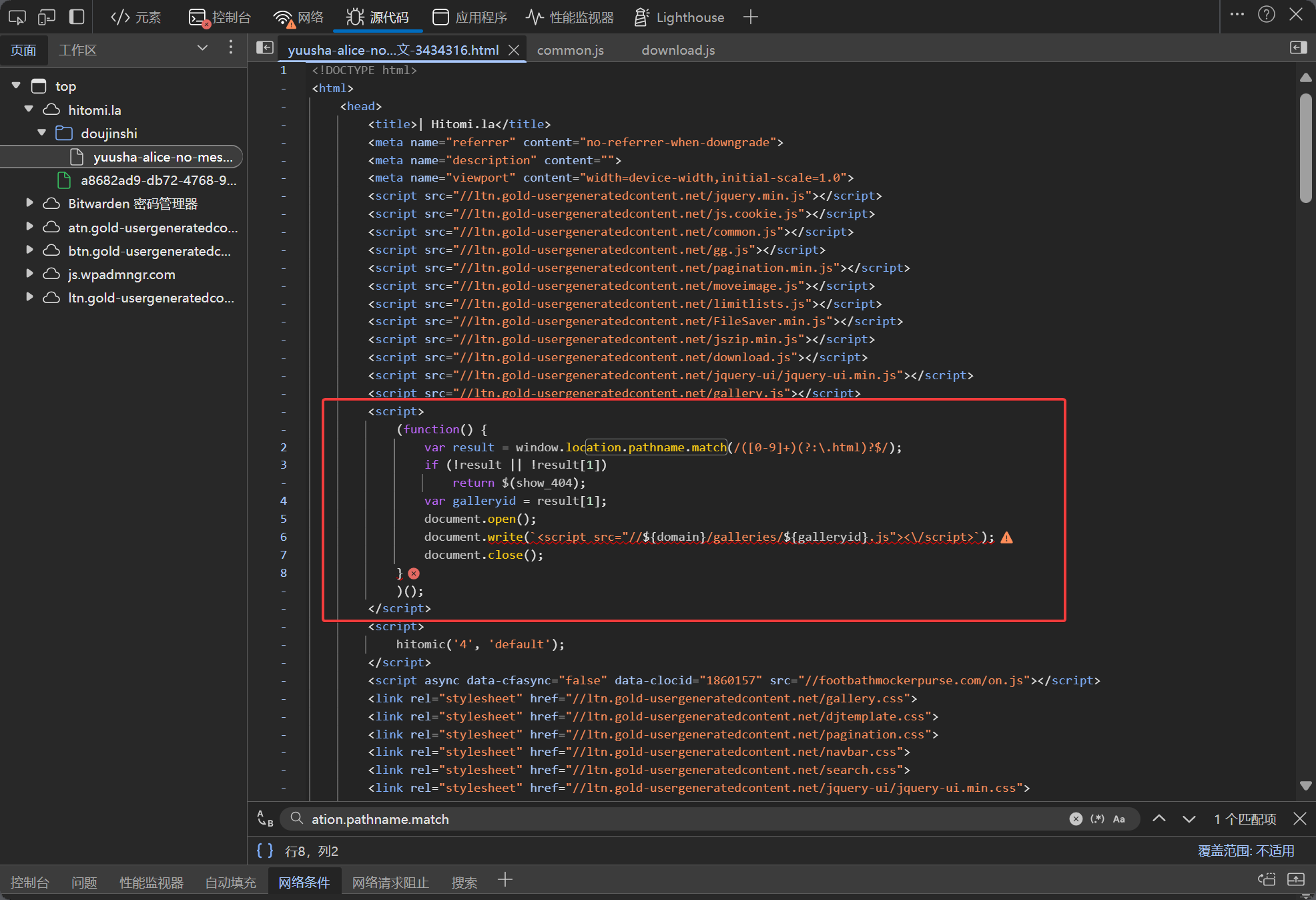
result = window.location.pathname.match(/([0-9]+)(?:\.html)?$/)
var galleryid = result[1]此代码借助正则表达式,从 URL 路径里提取最后的数字部分。这部分数字就是漫画的 ID。
基于此,可通过 Python 实现漫画 ID 的提取及galleryinfo的获取:
import json
import re
def get_galleryid(url):
"""
从 URL 路径提取 ID
url is str
"""
pattern = r'(\d+)\.html'
match = re.search(pattern, url)
if match:
return match.group(1) # 返回捕获组中的数字部分
else:
return None
galleryid = get_galleryid(url)
info_url = f'https://ltn.gold-usergenera**********.net/galleries/{galleryid}.js'
info_url = f'https://ltn.gold-usergenera**********.net/galleries/{galleryid}.js'
# more response code
info = json.loads(response.text.replace('var galleryinfo = ', ''))接下来就是获取图片的具体下载链接了。
之前在 download.js 可以找到,图片的下载链接是通过 url_from_url_from_hash(galleryid, image, 'webp') 来生成的。 image 为 object,对应的是 galleryinfo 里的 files 数列的每个元素。
在控制台搜索 url_from_url_from_hash 可以在 common.js 里找到几条相关的函数和变量。
function subdomain_from_url()full_path_from_hash()real_full_path_from_hash()url_from_url_from_hash()url_from_hash()ggdomain2
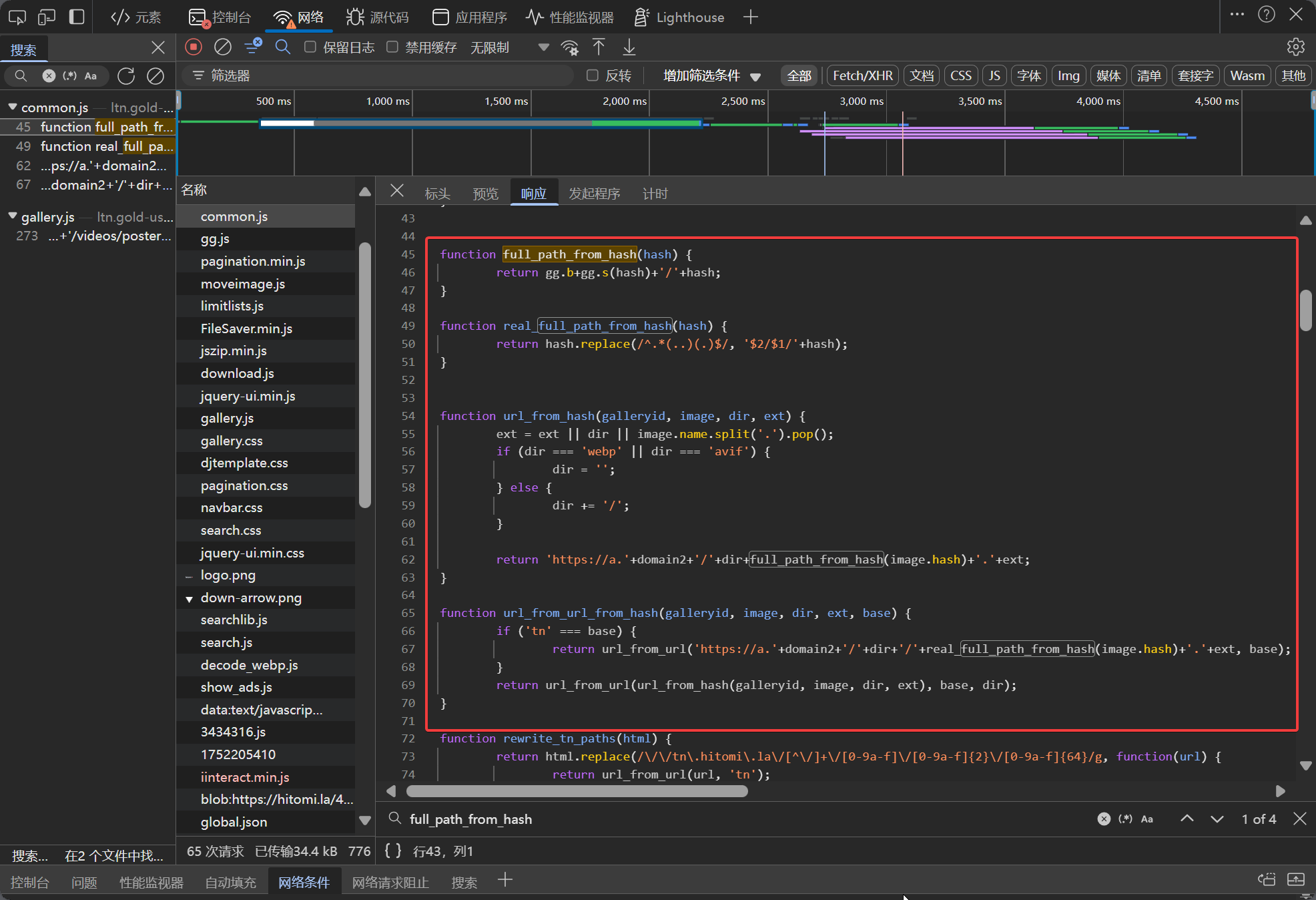
这些函数的核心作用是解析并生成图片下载链接,其中url_from_url_from_hash为入口函数。
值得注意的是,gg 是一个全局变量,其定义来自https://ltn.gold-usergenera**********.net/gg.js?_=时间戳——该文件内容可能动态变化,因此需每次请求时重新获取。
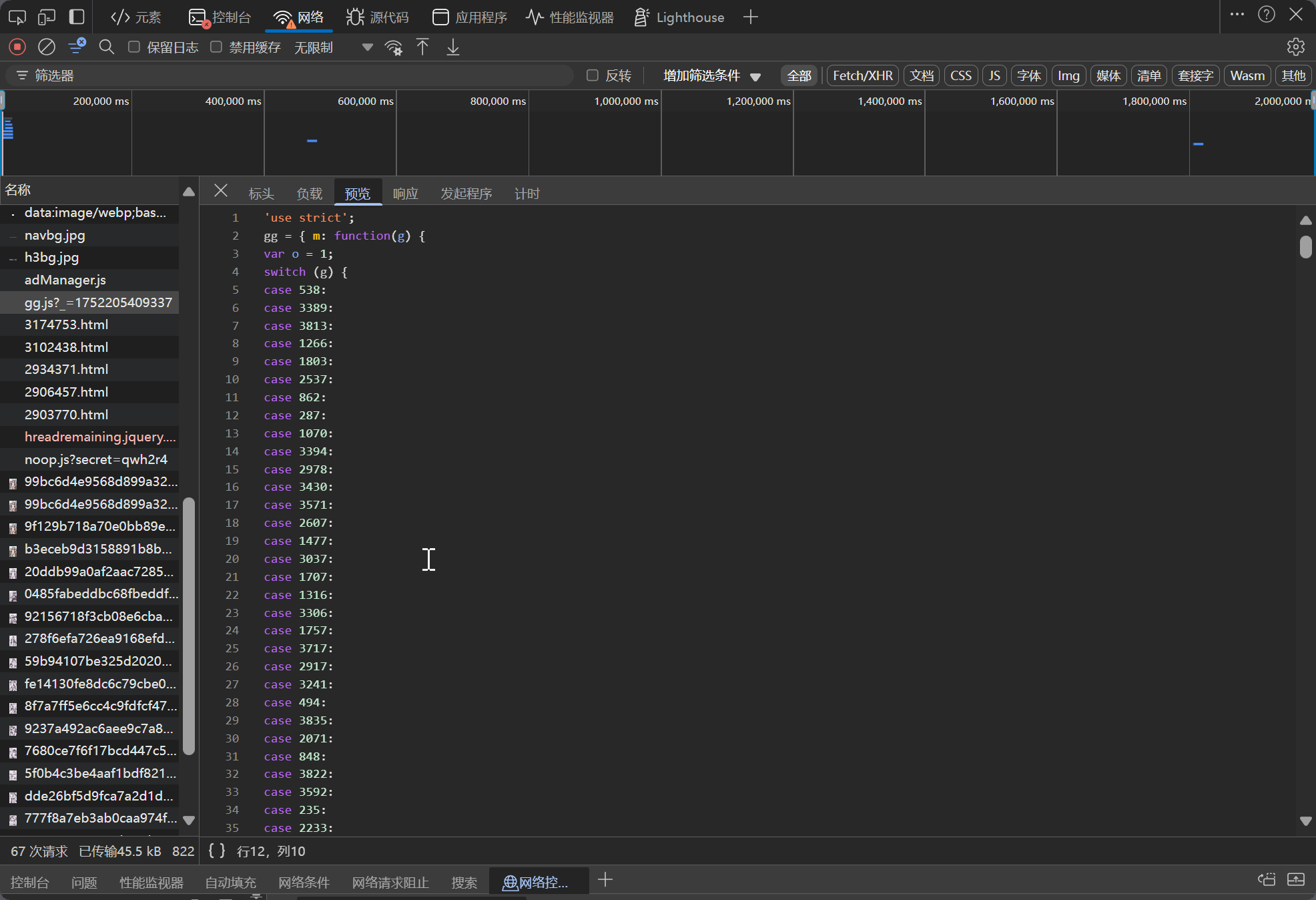
每次都人工解析 gg.js 代码并转成 Python 代码是不太现实的,所以我考虑直接用 Python 运行 JS 代码
感谢互联网,在 python 运行 JS 代码的库有几个 PyExecJS、PyV8、Js2Py,但这些都已经很久没有维护了。选择了 Js2Py,因为它是最新更新的(几年前更新的),它不支持最新的 Python 版本,但可以使用 a-j-albert/Js2Py---supports-python-3.13 的修复版本。
pip install git+https://github.com/a-j-albert/Js2Py---supports-python-3.13.git该处代码为获取像 1752202801/1059 这样的路径
import js2py
# more code
js_context = js2py.EvalJs()
js_context.execute(ggjs)
js_context.execute('''
function get(hash) {
return gg.b+gg.s(hash);
}
''')
print(js_context.get(hash))引入了 js2py 库,那干脆就直接用 js2py 库来运行 JS 代码,动态生成图片下载链接。
随便写了一段代码用来测试一下,果不其然,报错了。Traceback 反馈是在运行 common.js 代码时报错。估计是 common.js 有些代码在 js2py 里运行有问题。删去 common.js 里的无关代码,只保留必须的函数和变量,再次运行,成功。
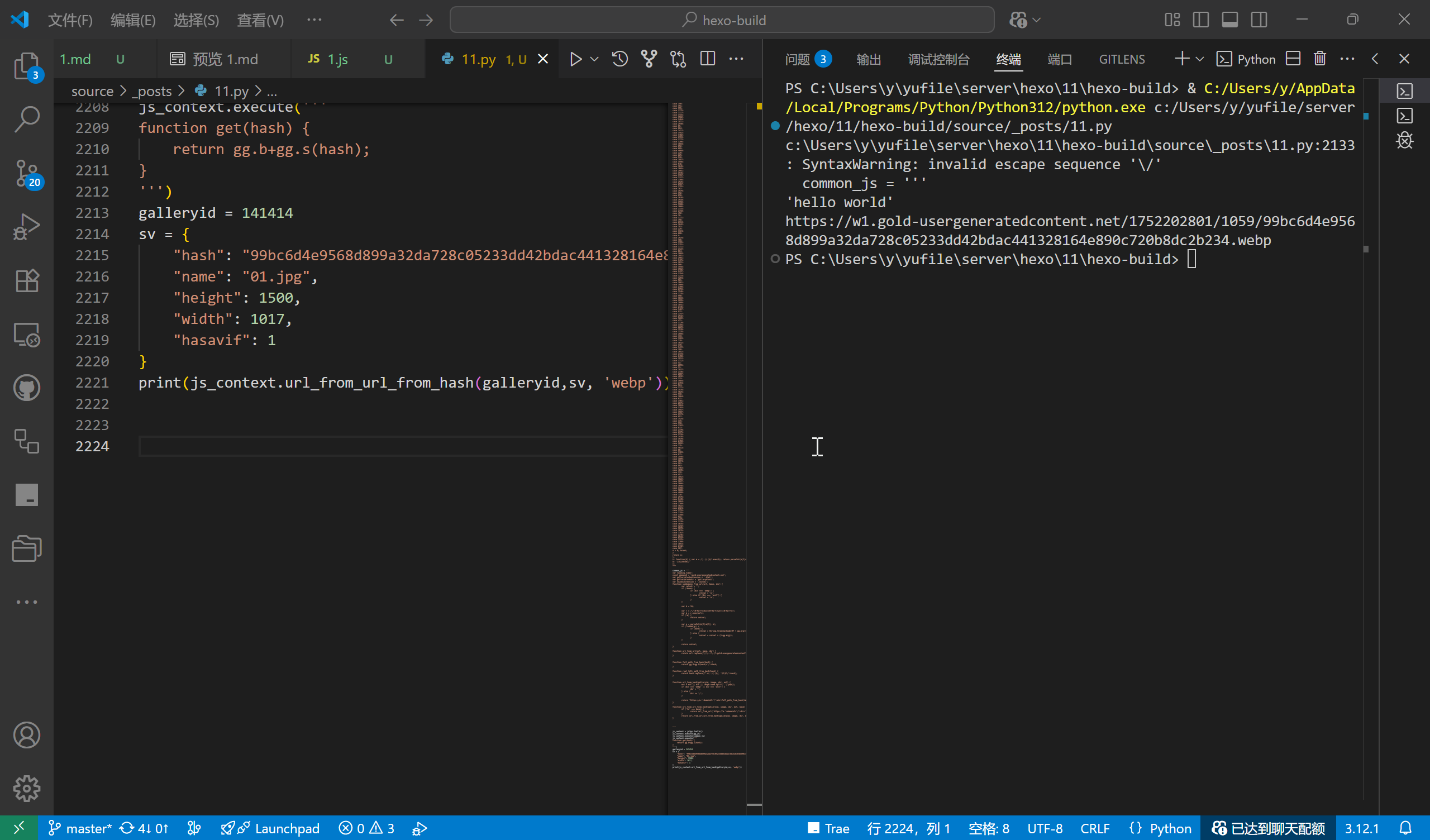
可以通过创建一个函数来删去 common.js 里的无关代码,避免无关代码的干扰。用 split 函数来分割 common.js 代码,删去后面无关的函数,删去前面的变量,仅保留中间的下载函数。在创建一个 Python 函数来获取必要的变量定义。
import re
def get_js_value(name,js,type='var'):
"""
通过正则表达式,从文本中查找并返回符合'var 名称 = 值;'格式的语句。
"""
r = rf'{type}\s+{re.escape(name)}\s*=\s*[^;]*;'
a= re.search(r, js)
if a:
return a.group(0)
else:
return None
def get_download_function(js):
"""获取关键函数及变量"""
a = js.split('function rewrite_tn_paths')[0].split('function subdomain_f')
b = 'function subdomain_f' + a[1]
c = get_js_value('domain2',a[0],'const')
return c + b
common_js=get_download_function(common_js)至此,我们已明确获取漫画信息及获取所有图片下载链接的逻辑了。
接下来还要构建一个用于发起网络请求的函数,考虑到网站在中国大陆可能存在访问问题,函数需支持代理设置及重试机制
import requests
import time
def fetch(fetch_url):
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"sec-ch-ua": "\"Not)A;Brand\";v=\"8\", \"Chromium\";v=\"138\", \"Microsoft Edge\";v=\"138\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "cross-site",
"referer": f"{base_url}",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0"
}
# 重试次数
max_retries = 3
retry_count = 0
while retry_count < max_retries:
try:
if proxies:
response = requests.get(fetch_url, headers=headers, timeout=10,proxies=proxies)
else:
response = requests.get(fetch_url, headers=headers, timeout=10)
response.raise_for_status() # 检查请求是否成功
# print(f"请求成功,状态码: {response.status_code}")
return response
except requests.exceptions.RequestException as e:
print(f"请求发生错误: {e}")
print(f"当前重试次数: [{retry_count}/{max_retries}]")
retry_count += 1
time.sleep(2) # 等待2秒后重试
print("请求失败")
return None别忘了我在前面说的要保存为 PDF、EPUB 等格式,下面就以 EPUB 格式作为示例。
传入一下必须的参数,使用 ebooklib 库来生成 EPUB 文件。具体怎么实现我就不详讲了(自己看代码去)
from ebooklib import epub
from PIL import Image
import os
import uuid
from pycountry import languages
import tempfile
import re
def safe_filename(filename):
"""移除文件名中的非法字符"""
return re.sub(r'[\\/:*?"<>|]', '', filename)
def epub_chapter_html_render(content,title="",type='text'):
"""
渲染章节内容为 HTML 格式
"""
if type == 'manga':
return f"""
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops" lang="zh" xml:lang="zh">
<head>
<meta charset="UTF-8" />
<title>{title}</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link href="./style/default.css" rel="stylesheet" type="text/css" />
</head>
<body>
<section id="ch01" epub:type="chapter">
<div class="container">
<img src="{content}" alt="{title}"/>
</div>
</section>
</body>
</html>
"""
elif type == 'text':
return f"""
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops" lang="zh" xml:lang="zh">
<head>
<meta charset="UTF-8" />
<title>{title}</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
</head>
<body>
<!-- 章节标题 -->
<section id="ch01" epub:type="chapter">
<header>
{'<h1>'+title+'</h1>' if title else ''}
</header>
<div class="container">
{content}
</div>
</section>
</body>
</html>
"""
def get_language_code(language_name):
try:
# 获取语言对象
lang = languages.get(name=language_name)
# 返回 ISO 639-1 双字母代码(若存在),否则返回 ISO 639-2 三字母代码
return lang.alpha_2 if hasattr(lang, 'alpha_2') else lang.alpha_3
except AttributeError:
print(f"语言名称不存在:{language_name}")
return language_name
def create_manga_epub(ebook_meta,image_paths,output_file):
"""
创建漫画EPUB文件
:param ebook_meta: 漫画元数据
:param output_path: 输出路径
:return: None
ebook_meta 示例
{
'title': f'{title}',
'author': f'{artists}',
'language': f'{language_localname}',
'tags': f'{tags}',
'parodys': f'{parodys}',
'date': f'{date}',
'description': f'{description}',
'type': f'{type}',
}
"""
# 检查传入参数
if not ebook_meta.get('title'):
raise ValueError("title 不能为空")
if image_paths:
for i in image_paths:
if not os.path.exists(i):
raise ValueError(f"image_paths 不存在:{i}")
else:
raise ValueError("image_paths 不能为空")
# os.makedirs(output_file, exist_ok=True)
# 创建EPUB书籍对象
book = epub.EpubBook()
# 设置元数据
book.set_identifier(str(uuid.uuid4()))
book.set_title(ebook_meta.get('title'))
book.set_language(get_language_code(ebook_meta.get('language')))
book.add_author(ebook_meta.get('author'))
book.add_metadata('DC', 'description', ebook_meta.get('description'))
# 生成详情页
book_intro_content = f"""
<p>书名:{ebook_meta.get('title')}</p>
<p>作者:{ebook_meta.get('author')}</p>
<p>语言:{ebook_meta.get('language')}</p>
<p>标签:{ebook_meta.get('tags')}</p>
<p>类型:{ebook_meta.get('type')}</p>
<p>系列:{ebook_meta.get('parodys')}</p>
<p>更新日期:{ebook_meta.get('date')}</p>
<p>简介:<p>
{ebook_meta.get('description')}</p>"""
book_intro = epub.EpubHtml(
title='详情',
file_name="intro.xhtml",
content=epub_chapter_html_render(book_intro_content,title='详情',type='text')
)
book.add_item(book_intro)
# 添加封面图片
cover_path = image_paths[0]
# 打开并检查封面图片
with Image.open(cover_path) as img:
width, height = img.size
if img.mode != 'RGB':
img = img.convert('RGB')
# 创建临时文件并获取文件对象和路径
with tempfile.NamedTemporaryFile(suffix='.jpg', delete=False) as temp_file:
temp_path = temp_file.name
img.save(temp_path, 'JPEG')
# 读取临时文件内容
with open(temp_path, 'rb') as cover_file:
cover_data = cover_file.read()
# 手动删除临时文件
os.remove(temp_path)
# cover_image = epub.EpubImage(
# uid='cover_image',
# file_name='images/cover.jpg',
# media_type = 'image/jpeg',
# content=cover_data
# )
# book.add_item(cover_image)
book.set_cover('images/cover.jpg', cover_data,create_page=True)
# 添加 css
css_content = '''
body {
font-family: "Microsoft YaHei", "STXihei", sans-serif;
font-size: 1.0em;
line-height: 1.6;
margin: 1em auto;
max-width: 800px;
padding: 0 1em;
text-align: justify;
}
h1 {
font-size: 28px;
text-align: center;
color: #91531d;
font-weight: normal;
margin-top: 2.5em;
margin-bottom: 2.5em;
}
h2 {
color: #1f4a92;
font-size: 22px;
font-family: "DK-XIAOBIAOSONG", "方正小标宋简体";
font-weight: normal;
border-bottom: solid 1px #1f4a92;
padding: 0.2em 0em 0.5em 0em;
text-indent: 0em;
}
p {
font-family: "DK-SONGTI", "方正宋三简体", "方正书宋", "宋体";
font-size: 16px;
text-indent: 2em;
}
blockquote {
font-size: 16px;
text-indent: 2em;
}
img {
width: 100%;
height: auto;
/* 居中 */
margin: 0 auto;
}
hr {
height: 10px;
border: none;
margin-top: 12px;
border-top: 10px groove #87ceeb;
}
hr {
color: #3dd9b6;
border: double;
border-width: 3px 5px;
border-color: #3dd9b6 transparent;
height: 1px;
overflow: visible;
margin-left: 20px;
margin-right: 20px;
position: relative;
}
hr:before,
hr:after {
content: '';
position: absolute;
width: 5px;
height: 5px;
border-width: 0 3px 3px 0;
border-style: double;
top: -3px;
background: radial-gradient(2px at 1px 1px, currentColor 2px, transparent 0) no-repeat;
}
hr:before {
transform: rotate(-45deg);
left: -20px;
}
hr:after {
transform: rotate(135deg);
right: -20px;
}
'''
book.add_item(epub.EpubItem(
uid='style_defaultyle',
file_name='style/default.css',
media_type='text/css',
content=css_content
))
book.toc = []
book.toc.append(epub.Link("intro.xhtml", "详情", "intro"))
# 处理所有图片并创建章节
chapters = []
for i, img_path in enumerate(image_paths):
# 读取图片数据
with open(img_path, 'rb') as img_file:
img_data = img_file.read()
# 确定文件扩展名
ext = os.path.splitext(img_path)[1].lower()
media_type = f'image/{ext[1:]}' if ext else 'image/jpeg'
# 创建图片项目
img_item = epub.EpubItem(
uid=f'image_{i}',
file_name=f'images/page_{i}{ext}',
media_type=media_type,
content=img_data
)
# 添加图片
book.add_item(img_item)
# 创建章节
chapter = epub.EpubHtml(
title=f'P{i}',
file_name=f'page_{i}.xhtml',
content=epub_chapter_html_render(f'images/page_{i}{ext}',type='manga')
)
# 添加章节
book.add_item(chapter)
# 添加到目录中
chapters.append(chapter)
book.toc.append(epub.Link(f'page_{i}.xhtml', f'P{i}', f'page_{i}'))
# 添加导航
book.add_item(epub.EpubNcx())
book.add_item(epub.EpubNav())
book.spine = [book_intro, *chapters]
# filename = safe_filename(ebook_meta.get('title'))
# file_path = os.path.join(output_file, filename)
# 写入文件
if os.path.exists(output_file):
os.remove(output_file)
epub.write_epub(output_file, book, {})
print(f'成功创建 EPUB: {output_file}')开始写完整的代码
至此,我们应该已经明确了解如何获取漫画信息及所有图片下载链接,并使用 Python 发起请求下载图片,保存为 EPUB 文件
接下来将开始编写完整的 Python 脚本,但先要理清一下思路.
- 设置基础 URL
- 获取 galleryinid
- 获取 galleryinfo
- 解析漫画信息
- 获取所有图片 url
- 遍历下载图片
- 生成 EPUB 文件
首先引入库
import requests
import time
import json
import re
import os
import js2py
from ebooklib import epub
from PIL import Image
import uuid
from pycountry import languages
import tempfile
# 安装 rich traceback
# from rich.traceback import install
# install()设置基础 URL
base_url = 'https://hit***.la/doujinshi/******'
gg_url = '***'
common_url = '******'获取并解析 galleryinfo
# 基础 URL
galleryid = get_galleryid(base_url)
# 获取 galleryinfo
info_url = f'https://ltn.gold-usergenera**********.net/galleries/{galleryid}.js'
info_url = f'https://ltn.gold-usergenera**********.net/galleries/{galleryid}.js'
info_response = fetch(info_url)
galleryinfo = json.loads(info_response.text.replace('var galleryinfo = ', ''))解析漫画信息并打印漫画信息
# 解析漫画信息
title = galleryinfo.get('title')
artists = []
for item in galleryinfo.get('artists'):
artists.append(item.get('artist'))
type = galleryinfo.get('type')
language_localname = galleryinfo.get('language_localname')
tags = []
for item in galleryinfo.get('tags'):
tags.append(item.get('tag'))
parodys = []
for item in galleryinfo.get('parodys'):
parodys.append(item.get('parody'))
date = galleryinfo.get('date')
# 打印详情
print(f'标题: {title}')
print(f'作者: {artists}')
print(f'类型: {type}')
print(f'语言: {language_localname}')
print(f'标签: {tags}')
print(f'系列: {parodys}')
print(f'页数: {len(galleryinfo.get("files"))}')
print(f'日期: {date}')
print(f'url: {base_url}')获取 gg.js 和 common.js 代码, 创建一个 js2py 环境, 并获取所有图片 url
# 获取 gg.js 和 common.js
gg_response = fetch(gg_url)
common_response = fetch(common_url)
gg_js = gg_response.text
common_js = common_response.text
common_js=get_download_function(common_js)
# 创建 js2py 环境
js_context = js2py.EvalJs()
js_context.execute(gg_js)
js_context.execute(common_js)
# 获取所有图片 url
urls = []
for file in galleryinfo['files']:
urls.append(js_context.url_from_url_from_hash(galleryid,file, 'webp'))全部的图片 URL 获取完了, 那么接下来就准备下载了
创建一个下载目录, 目录名称可以为 {title} - {artists} - {language_localname}. 考虑到可能 {title} 等中存在特殊字符导致程序报错. 创建一个函数用于生成安全的文件名.
def safe_filename(filename):
"""移除文件名中的非法字符"""
return re.sub(r'[\\/:*?"<>|]', '', filename)
# 创建下载目录
download_dir = safe_filename(f'{title} - {artists} - {language_localname}')
os.makedirs(download_dir, exist_ok=True)可以考虑在文件夹创建 metadata.json 文件用于存放漫画元信息
# 保存 metadata (galleryinfo)
metadata_file = os.path.join(download_dir, 'metadata.json')
with open(metadata_file, 'w',encoding='utf-8') as f:
json.dump(galleryinfo, f, indent=4,ensure_ascii=False )开始遍历下载图片
# 下载图片
print('开始下载')
filename = 0
for url in urls:
print(f'下载进度: [{filename+1}/{len(urls)}]',end='\r')
filepath = os.path.join(download_dir, str(filename)+'.webp')
response = fetch(url)
with open(filepath, 'wb') as f:
f.write(response.content)
print(f'下载完成: [{filename}/{len(urls)}], 大小: {len(response.content)} bytes')
filename += 1
print('下载完成')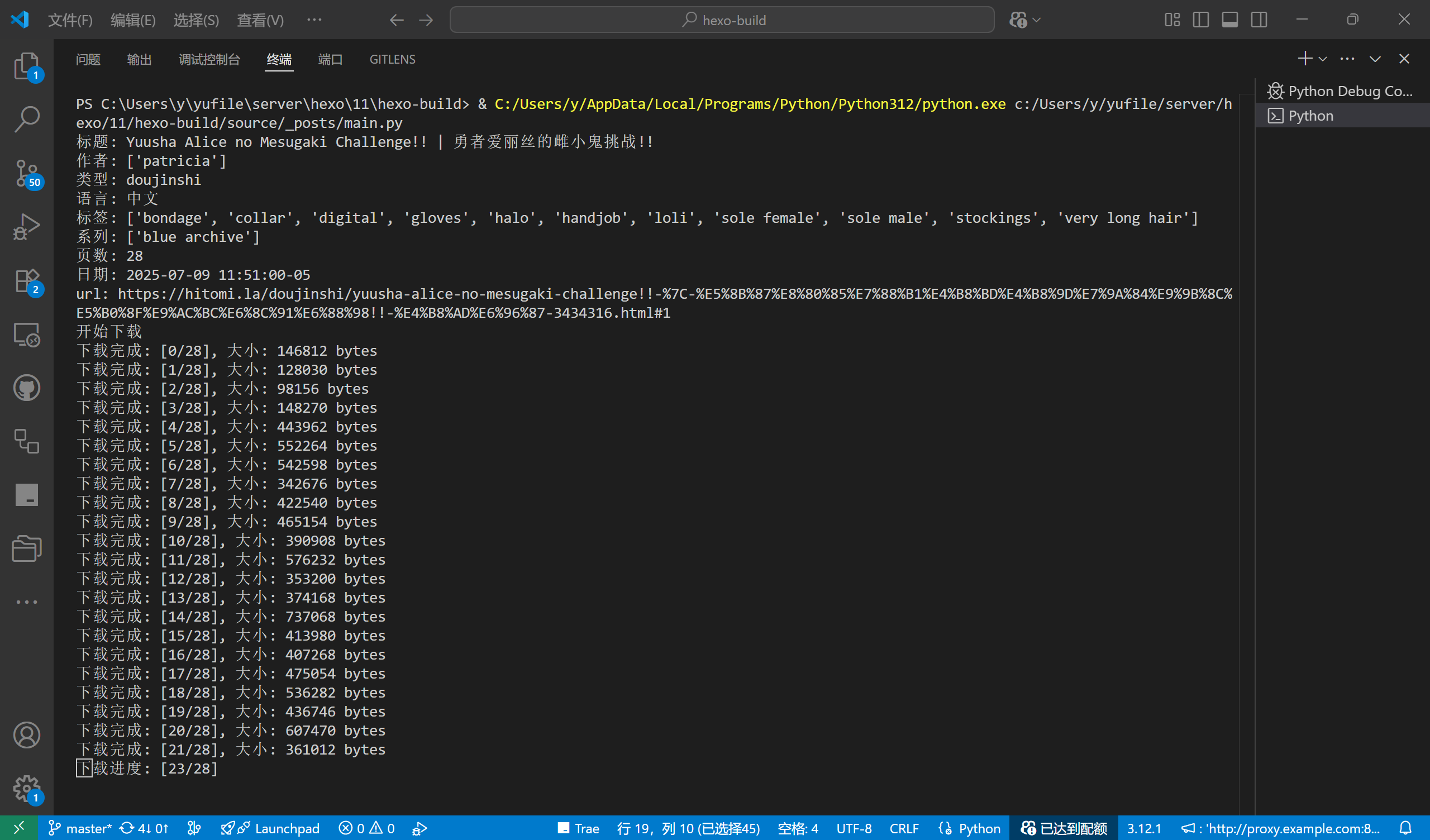
生成 ebook_info 字典,再运作 create_manga_epub() 生成 epub 文件。
ebook_info = {
'title': f'{title}',
'author': f'{artists}',
'language': f'{language}',
'tags': f'{tags}',
'parodys': f'{parodys}',
'date': f'{date}',
'type': f'{type}',
}
output_file = f'{download_dir}.epub'
print('创建 EPUB 中...')
create_manga_epub(ebook_info,filepaths,output_file)最后完整的代码如下
import requests
import time
import json
import re
import os
import js2py
from ebooklib import epub
from PIL import Image
import uuid
from pycountry import languages
import tempfile
# 安装 rich traceback
from rich.traceback import install
install()
# 基础设置
base_url = ''
gg_url = ''
common_url = ''
proxies = {
# 'http': 'http://proxy.example.com:8080',
# 'https': 'http://proxy.example.com:8080'
}
# 定义函数
def safe_filename(filename):
"""移除文件名中的非法字符"""
return re.sub(r'[\\/:*?"<>|]', '', filename)
def get_galleryid(url):
"""
从 URL 路径提取 ID
url is str
"""
pattern = r'(\d+)\.html'
match = re.search(pattern, url)
if match:
return match.group(1) # 返回捕获组中的数字部分
else:
raise ValueError("galleryid 提取失败,请检查 URL")
def fetch(fetch_url):
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"sec-ch-ua": "\"Not)A;Brand\";v=\"8\", \"Chromium\";v=\"138\", \"Microsoft Edge\";v=\"138\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "cross-site",
"referer": f"{base_url}",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0"
}
# 重试次数
max_retries = 3
retry_count = 0
while retry_count < max_retries:
try:
if proxies:
response = requests.get(fetch_url, headers=headers, timeout=10,proxies=proxies)
else:
response = requests.get(fetch_url, headers=headers, timeout=10)
response.raise_for_status() # 检查请求是否成功
# print(f"请求成功,状态码: {response.status_code}")
return response
except requests.exceptions.RequestException as e:
print(f"请求发生错误: {e}")
print(f"当前重试次数: [{retry_count}/{max_retries}]")
retry_count += 1
time.sleep(2) # 等待2秒后重试
print("请求失败")
return None
def get_js_value(name,js,type='var'):
"""
通过正则表达式,从文本中查找并返回符合'var 名称 = 值;'格式的语句。
"""
r = rf'{type}\s+{re.escape(name)}\s*=\s*[^;]*;'
a= re.search(r, js)
if a:
return a.group(0)
else:
return None
def get_download_function(js):
"""获取关键函数及变量"""
a = js.split('function rewrite_tn_paths')[0].split('function subdomain_f')
b = 'function subdomain_f' + a[1]
c = get_js_value('domain2',a[0],'const')
return c + b
def epub_chapter_html_render(content,title="",type='text'):
"""
渲染章节内容为 HTML 格式
"""
if type == 'manga':
return f"""
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops" lang="zh" xml:lang="zh">
<head>
<meta charset="UTF-8" />
<title>{title}</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link href="./style/default.css" rel="stylesheet" type="text/css" />
</head>
<body>
<section id="ch01" epub:type="chapter">
<div class="container">
<img src="{content}" alt="{title}"/>
</div>
</section>
</body>
</html>
"""
elif type == 'text':
return f"""
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops" lang="zh" xml:lang="zh">
<head>
<meta charset="UTF-8" />
<title>{title}</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
</head>
<body>
<!-- 章节标题 -->
<section id="ch01" epub:type="chapter">
<header>
{'<h1>'+title+'</h1>' if title else ''}
</header>
<div class="container">
{content}
</div>
</section>
</body>
</html>
"""
def get_language_code(language_name):
try:
# 获取语言对象
lang = languages.get(name=language_name)
# 返回 ISO 639-1 双字母代码(若存在),否则返回 ISO 639-2 三字母代码
return lang.alpha_2 if hasattr(lang, 'alpha_2') else lang.alpha_3
except AttributeError:
print(f"语言名称不存在:{language_name}")
return language_name
def create_manga_epub(ebook_meta,image_paths,output_file):
"""
创建漫画EPUB文件
:param ebook_meta: 漫画元数据
:param output_path: 输出路径
:return: None
ebook_meta 示例
{
'title': f'{title}',
'author': f'{artists}',
'language': f'{language_localname}',
'tags': f'{tags}',
'parodys': f'{parodys}',
'date': f'{date}',
'description': f'{description}',
'type': f'{type}',
}
"""
# 检查传入参数
if not ebook_meta.get('title'):
raise ValueError("title 不能为空")
if image_paths:
for i in image_paths:
if not os.path.exists(i):
raise ValueError(f"image_paths 不存在:{i}")
else:
raise ValueError("image_paths 不能为空")
# os.makedirs(output_file, exist_ok=True)
# 创建EPUB书籍对象
book = epub.EpubBook()
# 设置元数据
book.set_identifier(str(uuid.uuid4()))
book.set_title(ebook_meta.get('title'))
book.set_language(get_language_code(ebook_meta.get('language')))
book.add_author(ebook_meta.get('author'))
book.add_metadata('DC', 'description', ebook_meta.get('description'))
# 生成详情页
book_intro_content = f"""
<p>书名:{ebook_meta.get('title')}</p>
<p>作者:{ebook_meta.get('author')}</p>
<p>语言:{ebook_meta.get('language')}</p>
<p>标签:{ebook_meta.get('tags')}</p>
<p>类型:{ebook_meta.get('type')}</p>
<p>系列:{ebook_meta.get('parodys')}</p>
<p>更新日期:{ebook_meta.get('date')}</p>
<p>简介:<p>
{ebook_meta.get('description')}</p>"""
book_intro = epub.EpubHtml(
title='详情',
file_name="intro.xhtml",
content=epub_chapter_html_render(book_intro_content,title='详情',type='text')
)
book.add_item(book_intro)
# 添加封面图片
cover_path = image_paths[0]
# 打开并检查封面图片
with Image.open(cover_path) as img:
width, height = img.size
if img.mode != 'RGB':
img = img.convert('RGB')
# 创建临时文件并获取文件对象和路径
with tempfile.NamedTemporaryFile(suffix='.jpg', delete=False) as temp_file:
temp_path = temp_file.name
img.save(temp_path, 'JPEG')
# 读取临时文件内容
with open(temp_path, 'rb') as cover_file:
cover_data = cover_file.read()
# 手动删除临时文件
os.remove(temp_path)
# cover_image = epub.EpubImage(
# uid='cover_image',
# file_name='images/cover.jpg',
# media_type = 'image/jpeg',
# content=cover_data
# )
# book.add_item(cover_image)
book.set_cover('images/cover.jpg', cover_data,create_page=True)
# 添加 css
css_content = '''
body {
font-family: "Microsoft YaHei", "STXihei", sans-serif;
font-size: 1.0em;
line-height: 1.6;
margin: 1em auto;
max-width: 800px;
padding: 0 1em;
text-align: justify;
}
h1 {
font-size: 28px;
text-align: center;
color: #91531d;
font-weight: normal;
margin-top: 2.5em;
margin-bottom: 2.5em;
}
h2 {
color: #1f4a92;
font-size: 22px;
font-family: "DK-XIAOBIAOSONG", "方正小标宋简体";
font-weight: normal;
border-bottom: solid 1px #1f4a92;
padding: 0.2em 0em 0.5em 0em;
text-indent: 0em;
}
p {
font-family: "DK-SONGTI", "方正宋三简体", "方正书宋", "宋体";
font-size: 16px;
text-indent: 2em;
}
blockquote {
font-size: 16px;
text-indent: 2em;
}
img {
width: 100%;
height: auto;
/* 居中 */
margin: 0 auto;
}
hr {
height: 10px;
border: none;
margin-top: 12px;
border-top: 10px groove #87ceeb;
}
hr {
color: #3dd9b6;
border: double;
border-width: 3px 5px;
border-color: #3dd9b6 transparent;
height: 1px;
overflow: visible;
margin-left: 20px;
margin-right: 20px;
position: relative;
}
hr:before,
hr:after {
content: '';
position: absolute;
width: 5px;
height: 5px;
border-width: 0 3px 3px 0;
border-style: double;
top: -3px;
background: radial-gradient(2px at 1px 1px, currentColor 2px, transparent 0) no-repeat;
}
hr:before {
transform: rotate(-45deg);
left: -20px;
}
hr:after {
transform: rotate(135deg);
right: -20px;
}
'''
book.add_item(epub.EpubItem(
uid='style_defaultyle',
file_name='style/default.css',
media_type='text/css',
content=css_content
))
book.toc = []
book.toc.append(epub.Link("intro.xhtml", "详情", "intro"))
# 处理所有图片并创建章节
chapters = []
for i, img_path in enumerate(image_paths):
# 读取图片数据
with open(img_path, 'rb') as img_file:
img_data = img_file.read()
# 确定文件扩展名
ext = os.path.splitext(img_path)[1].lower()
media_type = f'image/{ext[1:]}' if ext else 'image/jpeg'
# 创建图片项目
img_item = epub.EpubItem(
uid=f'image_{i}',
file_name=f'images/page_{i}{ext}',
media_type=media_type,
content=img_data
)
# 添加图片
book.add_item(img_item)
# 创建章节
chapter = epub.EpubHtml(
title=f'P{i}',
file_name=f'page_{i}.xhtml',
content=epub_chapter_html_render(f'images/page_{i}{ext}',type='manga')
)
# 添加章节
book.add_item(chapter)
# 添加到目录中
chapters.append(chapter)
book.toc.append(epub.Link(f'page_{i}.xhtml', f'P{i}', f'page_{i}'))
# 添加导航
book.add_item(epub.EpubNcx())
book.add_item(epub.EpubNav())
book.spine = [book_intro, *chapters]
# filename = safe_filename(ebook_meta.get('title'))
# file_path = os.path.join(output_file, filename)
# 写入文件
if os.path.exists(output_file):
os.remove(output_file)
epub.write_epub(output_file, book, {})
print(f'成功创建EPUB: {output_file}')
def main():
galleryid = get_galleryid(base_url)
# 获取 galleryinfo
info_url = f'https://ltn.gold-u*********.net/galleries/{galleryid}.js'
info_response = fetch(info_url)
galleryinfo = json.loads(info_response.text.replace('var galleryinfo = ', ''))
# 解析漫画信息
title = galleryinfo.get('title')
artists = []
for item in galleryinfo.get('artists'):
artists.append(item.get('artist'))
type = galleryinfo.get('type')
language = galleryinfo.get('language')
language_localname = galleryinfo.get('language_localname')
tags = []
for item in galleryinfo.get('tags'):
tags.append(item.get('tag'))
parodys = []
for item in galleryinfo.get('parodys'):
parodys.append(item.get('parody'))
date = galleryinfo.get('date')
# 打印详情
print(f'标题: {title}')
print(f'作者: {artists}')
print(f'类型: {type}')
print(f'语言: {language_localname}({language})')
print(f'标签: {tags}')
print(f'系列: {parodys}')
print(f'页数: {len(galleryinfo.get("files"))}')
print(f'日期: {date}')
print(f'url: {base_url}')
# # 获取所有图片 hash
# hashes = []
# for item in galleryinfo['files']:
# hashes.append(item['hash'])
# 获取 gg.js 和 common.js
gg_response = fetch(gg_url)
common_response = fetch(common_url)
gg_js = gg_response.text
common_js = common_response.text
common_js=get_download_function(common_js)
# 创建 js2py 环境
js_context = js2py.EvalJs()
js_context.execute(gg_js)
js_context.execute(common_js)
# 获取所有图片 url
urls = []
for file in galleryinfo['files']:
urls.append(js_context.url_from_url_from_hash(galleryid,file, 'webp'))
# 创建下载目录
download_dir = safe_filename(f'{title} - {artists} - {language_localname}')
os.makedirs(download_dir, exist_ok=True)
# 保存 metadata (galleryinfo)
metadata_file = os.path.join(download_dir, 'metadata.json')
with open(metadata_file, 'w',encoding='utf-8') as f:
json.dump(galleryinfo, f, indent=4,ensure_ascii=False )
# 下载图片
print('开始下载')
filename = 0
filepaths = []
for url in urls:
print(f'下载进度: [{filename+1}/{len(urls)}]',end='\r')
filepath = os.path.join(download_dir, str(filename)+'.webp')
response = fetch(url)
with open(filepath, 'wb') as f:
f.write(response.content)
print(f'下载完成: [{filename+1}/{len(urls)}], 大小: {len(response.content)} bytes')
filename += 1
filepaths.append(filepath)
print('下载完成')
ebook_info = {
'title': f'{title}',
'author': f'{artists}',
'language': f'{language}',
'tags': f'{tags}',
'parodys': f'{parodys}',
'date': f'{date}',
'type': f'{type}',
}
output_file = f'{download_dir}.epub'
print('创建 EPUB 中...')
create_manga_epub(ebook_info,filepaths,output_file)
# 运行主函数
if __name__ == '__main__':
main()BUG 修复
使用 epub.EpubHtml 生成的对象,定义内容时,会忽略 <head> 元素中的任何内容。也就是包含在的 <head> 的 <link> 元素将不会在出现在 xhtml 中。
想添加 css 的方法如下,使用 chapter.add_item(default_css)
default_css = epub.EpubItem()
book.add_item(default_css)
chapter = epub.EpubHtml()
chapter.add_item(default_css)那么本 create_manga_epub() 的函数要作以下修改
# 删去前面的 book.add_item(book_intro)
# ===================
# 修改 css 添加
# book.add_item(epub.EpubItem(
# uid='style_defaultyle',
# file_name='style/default.css',
# media_type='text/css',
# content=css_content
# ))
# 改为
default_css=epub.EpubItem(
uid='style_defaul',
file_name='style/default.css',
media_type='text/css',
content=css_content
)
book.add_item(default_css)
book_intro.add_item(default_css)
book.add_item(book_intro)
# ===================
# 在章节添加到 EPUB 前先给 chapter 加上 css
chapter.add_item(default_css)
book.add_item(chapter)对于已经下载好的,可以在运行这段代码给当前目录下所有 EPUB 添加 <link> 元素。
import os
import re
import zipfile
import tempfile
import shutil
# 要添加的CSS链接
CSS_LINK = '<link href="style/default.css" rel="stylesheet" type="text/css"/>'
def add_css_to_epubs():
# 获取当前目录所有EPUB文件
epub_files = [f for f in os.listdir('.')
if os.path.isfile(f) and f.lower().endswith('.epub')]
for epub in epub_files:
process_epub(epub)
def process_epub(epub_path):
# 创建临时工作目录
with tempfile.TemporaryDirectory() as tmp_dir:
# 解压EPUB到临时目录
with zipfile.ZipFile(epub_path, 'r') as zf:
zf.extractall(tmp_dir)
# 遍历所有XHTML文件并修改
for root, _, files in os.walk(tmp_dir):
for file in files:
if file.lower().endswith(('.xhtml', '.html')):
file_path = os.path.join(root, file)
add_css_link(file_path)
new_epub = epub_path + '.new'
with zipfile.ZipFile(new_epub, 'w') as new_zf:
# 添加mimetype(无压缩)
mimetype_path = os.path.join(tmp_dir, 'mimetype')
if os.path.exists(mimetype_path):
new_zf.write(mimetype_path, 'mimetype', compress_type=zipfile.ZIP_STORED)
for root, _, files in os.walk(tmp_dir):
for file in files:
if file == 'mimetype':
continue
full_path = os.path.join(root, file)
rel_path = os.path.relpath(full_path, tmp_dir)
new_zf.write(full_path, rel_path)
# 替换原始文件
shutil.move(new_epub, epub_path)
print(f"已处理: {epub_path}")
def add_css_link(file_path):
with open(file_path, 'r+', encoding='utf-8') as f:
content = f.read()
# 使用正则查找<head>标签(带属性)
head_match = re.search(r'<head\b[^>]*>', content)
if head_match:
head_tag = head_match.group(0)
new_content = content.replace(
head_tag,
head_tag + '\n ' + CSS_LINK,
1 # 只替换第一个匹配项
)
f.seek(0)
f.write(new_content)
f.truncate()
if __name__ == '__main__':
add_css_to_epubs()
print("所有EPUB文件处理完成!")Improve
尽可能不使用第三方库(js2py)
特别感谢 leaphy 对 gg.js 中正则表达式实现的拆解分析。
可以通过下列代码实现 gg.js 的功能
import re
class GG:
def __init__(self, js_code):
self.b = self.parse_b_property(js_code)
self.case_values = self.parse_case_values(js_code)
@staticmethod
def parse_b_property(js_code):
# 匹配 b
match = re.search(r'b\s*:\s*["\'](.*?)["\']', js_code)
return match.group(1) if match else None
@staticmethod
def parse_case_values(js_code):
# 匹配 case
case_pattern = re.compile(r"case\s+(\d+):")
cases = case_pattern.findall(js_code)
return set(map(int, cases))
def m(self, g):
return 1 if g in self.case_values else 0
@staticmethod
def s(h):
match = re.search(r'(..)(.)$', h)
if match:
swapped = match.group(2) + match.group(1)
return str(int(swapped, 16))
return '0'
gg = GG(gg_js)
print(f'gg: {gg}')
print(f"gg.b: {gg.b}")
print("gg.s('4d9433e700052a6f9c2a56a48c15830d864f8bb2abe1cccb711b07a491751d8c')")
print(gg.s('4d9433e700052a6f9c2a56a48c15830d864f8bb2abe1cccb711b07a491751d8c'))common.js 的实现
import re
# 导入 GG 类
from ggpy import GG
# 模拟数据
gg = GG(gg_js)
# 全局变量(与 JavaScript 中一致)
# 可以考虑实时获取
domain2 = 'gold-usergeneratedcontent.net'
def subdomain_from_url(url, base, dir):
retval = ''
if not base:
if dir == 'webp':
retval = 'w'
elif dir == 'avif':
retval = 'a'
pattern = re.compile(r'\/[0-9a-f]{61}([0-9a-f]{2})([0-9a-f])')
match = pattern.search(url)
if not match:
return retval
hex_part = match.group(2) + match.group(1)
try:
g = int(hex_part, 16)
except ValueError:
return retval
if base:
char_code = 97 + gg.m(g)
retval = chr(char_code) + base
else:
retval += str(1 + gg.m(g))
return retval
def url_from_url(url, base, dir):
pattern = r'//..?\.(?:gold-usergeneratedcontent\.net|hitomi\.la)/'
replacement = '//' + subdomain_from_url(url, base, dir) + '.' + domain2 + '/'
return re.sub(pattern, replacement, url, count=1)
def full_path_from_hash(hash_str):
return f"{gg.b}{gg.s(hash_str)}/{hash_str}"
def real_full_path_from_hash(hash_str):
if len(hash_str) < 3:
return hash_str
return f"{hash_str[-1]}/{hash_str[-2]}/{hash_str}"
def url_from_hash(galleryid, image, dir, ext=None):
if ext is None:
ext = dir or image.name.split('.')[-1]
dir_path = '' if dir in ('webp', 'avif') else f"{dir}/"
full_path = full_path_from_hash(image["hash"])
return f"https://a.{domain2}/{dir_path}{full_path}.{ext}"
def url_from_url_from_hash(galleryid, image, dir, ext=None, base=None):
if base == 'tn':
path = real_full_path_from_hash(image.hash)
url = f"https://a.{domain2}/{dir}/{path}.{ext}"
return url_from_url(url, base, dir)
else:
url = url_from_hash(galleryid, image, dir, ext)
return url_from_url(url, base, dir)测试文件,解压密码:123456
気に入ったならばコメントを残してくださいね~